|
大量のデータから「知識」「情報」を発掘する!

|
赤間 世紀 著
2010年12月10日発売
A5判
160ページ
定価 \2,530(本体 \2,300)
|
|
ISBN978-4-7775-1567-7 C3004 \2300E
|
 |
≪大規模データを「分析」「予測」する≫
「データ・マイニング」は、一見して無意味なデータから、有用な「知識」や「情報」を抽出する技術です。
大量のデータをデータベース処理することによって、隠れた「パターン」を見つけ出し、「隠れた知識」を発見するのが目的です。
コンピュータの高性能化によって、企業などでも大量のデータを分析できるようになったことから、注目されるようになり、「データ・マイニング」を行なうシステムやツールも多く開発されています。
「データ・マイニング」の理論やシステムは、初歩的なものから高度なものまでさまざまなものがあり、そのため、総合的な理解は難しくなっています。
そこで本書は、「データ・マイニング」の全体像を明らかにし、主な手法を分かりやすく解説しました。
|
|
| ■ 主な内容 ■ |
|
まえがき
| [1.1] データ・マイニングとは |
[1.2] 歴史 |
| [2.1] データ |
[2.2] データベース |
| [2.3] データ・ウェアハウス |
[2.4] 意思決定支援システム |
| [3.1] データ・マイニングの概要 |
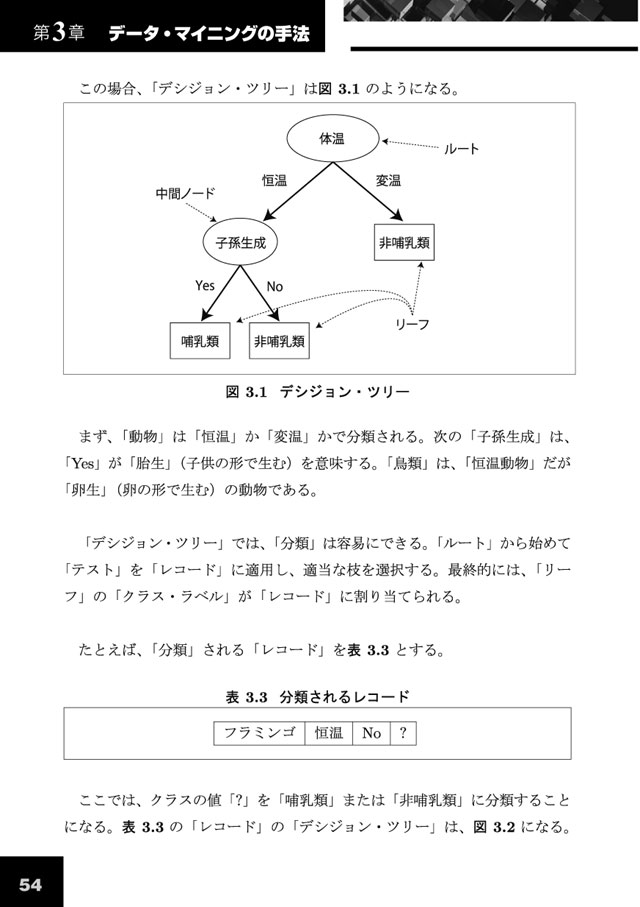
[3.2] 分類 |
| [3.3] 連関 |
[3.4] クラスタリング |
| [3.5] RFM分析 |
[3.6] OLAP |
| [3.7] 統計分析 |
[3.8] 高度な手法 |
| [4.1] データ・マイニングの応用分野 |
[4.2] データ・マイニング・システムのアーキテクチャ |
| [4.3] データ・マイニングの今後 |
|
参考
索引
※ 内容が一部異なる場合があります。発売日は、東京の発売日であり、地域によっては1〜2日程度遅れることがあります。あらかじめご了承ください。
|
|
|
|